Crafting Frontend: Spotify Playlist — Frontend System Architecture
 Photo by Danny Howe
Photo by Danny HoweThis post is part of the series Crafting Frontend, the Frontend Architecture version.
These are my notes from a frontend architecture interview I had in the past. Here we will talk about the challenge (a Spotify Playlist), and think together about the whole architecture: API request/payload, Components, State Management, and Performance Optimizations we can do.
Let's do it!
Requirements & Clarifications
The challenge is the following: we should design a music playlist, similar to Spotify. It needs to list a list of songs, play a song, go to the next one, go to the previous one, and stop the song.
It starts very generically and we need to build the foundation by asking clarifying questions.
These are good starting points:
- How many songs per playlist are possible to store?
- if infinite, you can start thinking about pagination (API architecture), image optimization, and list virtualization (web performance)
- If at most 10/20, maybe it's not necessary to think about all that listed above
- Is it possible to add or remove songs from the playlist? Should I care about it for this current design?
- This an interesting question, because if the answer is “yes”, we should be careful with how we structure our state data structure. e.g. if removing a song, the previous song's should “point” to the next song when the user clicks “next”. The same for the “previous”.
- Also, we should probably design a new API endpoint to handle the songs list update: adding or removing a song from a playlist doesn't only update on the frontend, but also in the database
- Do I need to handle authentication? How will auth for this application be?
- It can open the scope to handle unlogged users: redirect page if you are not the owner of the playlist (maybe think about 401 — unauthorized), only able to see “public” playlists
- It can have a simple auth token and you just need to send it to the backend through API requests, so you probably don't need to focus on it that much
- Should we think about responsive design (desktop and mobile)?
- In this case, it doesn't matter that much if we focus on one or the other because the UI and how we handle user behavior will be pretty much the same for both.
- But this question is interesting because mobile devices are less powerful, and you can focus on the performance optimizations for this specific device
- Also, it's always good to show that you care about responsive design (as mobile is eating the world)
In general, think about questions that
- will increase or close the scope of the architecture
- e.g. for an increase: adding a new feature, think about mobile and desktop
- e.g. for closing the scope: asking about features and the answer is “no need for this scope”
- e.g. should handle authenticated user
- will change how think about the architecture
- e.g. the size of the list
- e.g. focus on mobile too — maybe need to tackle performance problems (should be asked)
From UI to components
This is probably one of the easiest parts of the design. I guess.
My process is to get every little part of the UI and think of it as a UI component or a part of a bigger component. Then I break down the components into a “tree” so I can understand the relationship between components.
Having this tree, it's even better and easier to visualize how we can design the data structure and how we should colocate it / be used by each component.
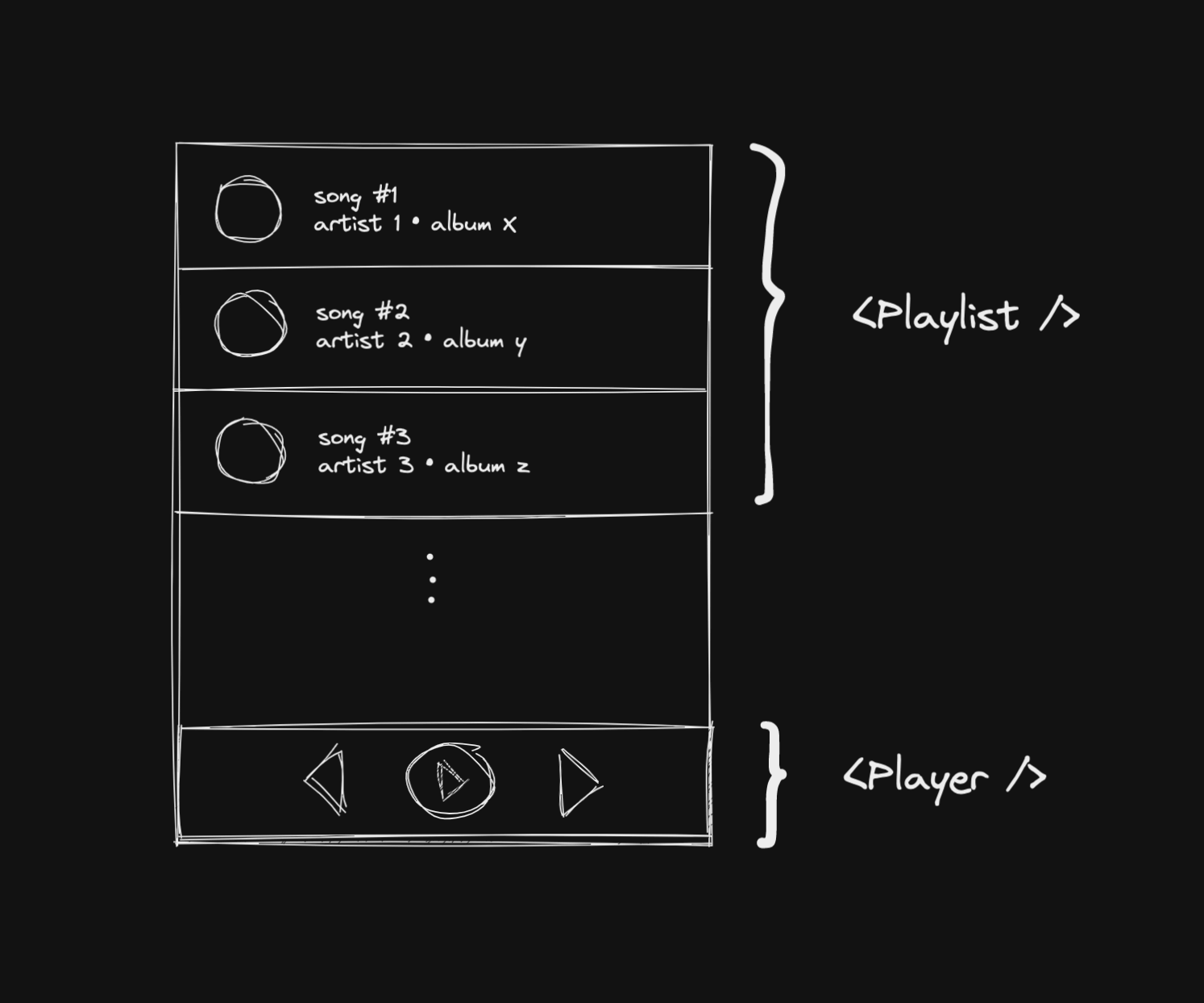
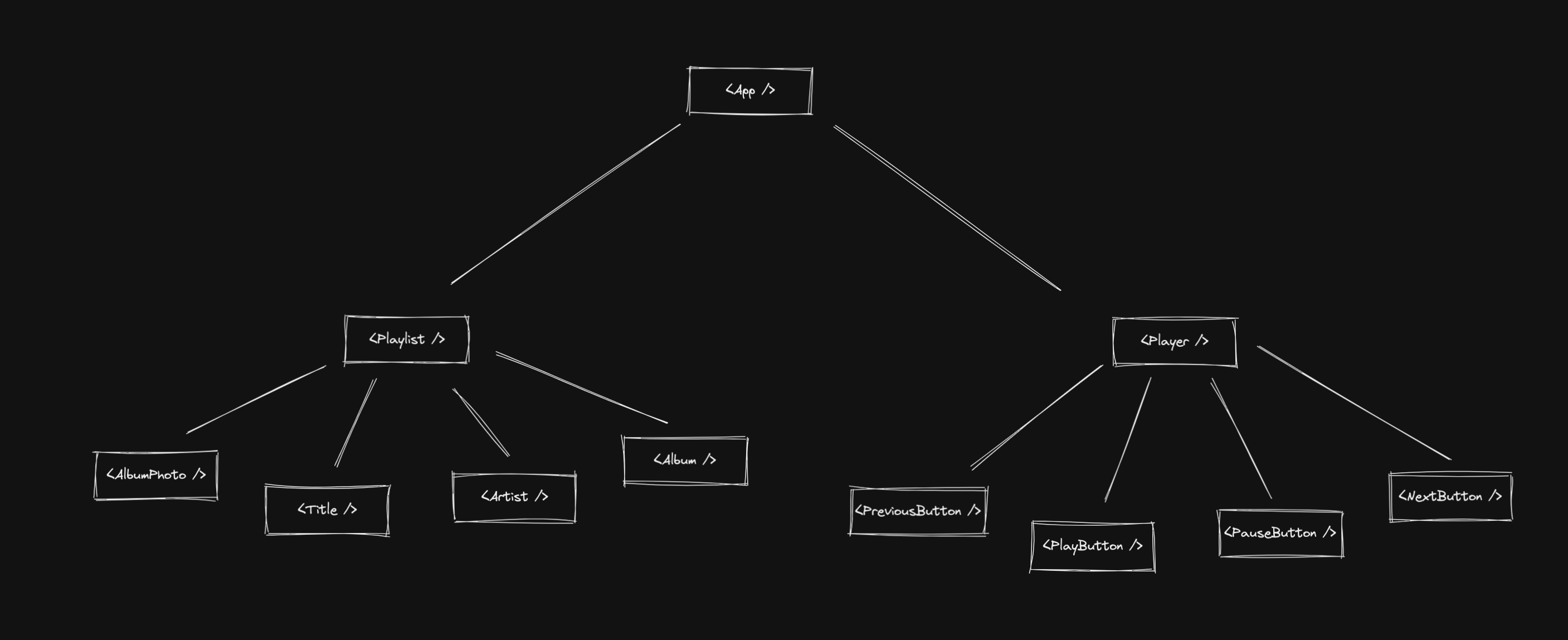
The first part is pretty obvious. We separate the playlist from the player. So now we know that we would have a Playlist and Player components.
And then we can break down each component into smaller components that combined will build up the whole UI component.
The <Playlist /> first: we can separate it into 4 smaller components. <AlbumPhoto />, <Title />, <Artist />, and <Album />.
The album photo is just the image rendered for the song in the list and the title, artist, and album are strings or information about the song.
The <Player /> is pretty similar: also 4 components. <PreviousButton />, <PlayButton />, <PauseButton />, and <NextButton />.
All 4 components are just buttons and will respond to user interactions.
Of course, we can break them down in different ways but this is how I first thought about it, and to be honest, I feel pretty good about it.
API Requests & Payload Interface
Now we should design how the client will interact with the server and the type interface of the data coming from the backend.
When designing this, the first thought that came to my mind is the idea of the client just doing a simple API request to the backend and the server responding a JSON data (that we can define its type interface later on).

One question you could ask is if we need to handle authentication. When I asked this question, the interviewer just answered that I could think I have a auth token and this is what I need to request the endpoint and get my data as a user.
A simple API endpoint would be something like this: /api/playlist/:id.
That way, you can just request this URL, pass the playlist id, and the auth token. It would return the playlist or a list of songs.
The :id could be just an integer number like /api/playlist/123 or a “UUID”/”ULID” like /api/playlist/01ARZ3NDEKTSV4RRFFQ69G5FAV. But I guess this is just an implementation detail.
To start the playlist interface, we first think about the song data we need to render all the necessary information in the UI. It would look like this:
interface Song {
id: string;
title: string;
artist: string;
album: string;
albumPhoto: string;
songUrl: string;
}
And the playlist interface is just a list of songs:
type Playlist = Song[];
The playlist can have a huge list of songs, so it's better if we paginate it, right? The data interface for pagination is simple as we commonly use a “pattern” for it:
interface Data {
playlist: Playlist;
page: number;
perPage: number;
pageCount: number;
totalCount: number;
previous: string | null;
next: string | null;
}
page: the current pageperPage: how many songs per pagepageCount: the number of pagestotalCount: the number of songs in totalprevious: the URL for the previous page (it can benullif the current page is the first one)next: the URL for the next page (it can benullif the current page is the last one)
Other two interesting ideas to discuss here are how we would handle the loading experience and the error handling.
Every time we request data from an API, we need to show a loader for the user while we are fetching the data. And if the request fails, we should handle this error.
The loader can be a loading spinner or a skeleton for example.
And an example of error handling is showing a text for different status codes
404: couldn't find the playlist401: you're not authorized to see this playlist. Re-authenticate and try again403: you're not allowed to see the playlist500: our server encountered a problem and we're fixing it
For each error code, we can show a different message to the user.
This is how we can think about the API request, the data type interface, and how we handle the loading and the error experience for the user.
State Management: handling client data
Let's recap what we should handle to enable the features for the users:
- It should play the current song
- It should be able to go to the next song
- It should be able to go to the previous song
- It should be able to highlight the current song in the playlist
We need a way to hold the data for the list and the current song. We can do it in a normalized way using objects or using arrays that can be more performant.
Just to recap, we have the song and the playlist interfaces:
interface Song {
id: string;
title: string;
artist: string;
album: string;
albumPhoto: string;
songUrl: string;
}
type Playlist = Song[];
Let's see how the normalized way would work first.
type PlaylistById = Record<string, Song>;
interface State {
currentSongId: number;
playlist: {
byId: PlaylistById;
allSongIds: number[];
};
}
Here we have the state interface. We have the currentSongId to hold the, well, the current song id. And the playlist. The playlist will contain the list of songs by id and all the song ids.
With the currentSongId, we can contemplate one of the features: getting the current song (to play and highlight it on the list).
But we also need to contemplate the other features as well: get the next and the previous songs based on the current song.
This is why we have the allSongIds in the playlist object. With that, we maintain the ids in an ordered way so we know what's the previous and the next ids. The problem is: every time we need to access the previous or the next id, we need to traverse this list, so we would have the time complexity of O(N), N being the number of songs in the list.
Another approach is to use arrays to handle that. At first, you'll think that it's counterintuitive to use arrays over hashmaps to improve performance, right? But in this case, we can use “almost” like hashmaps and keep the O(1) time complexity. Let's see how it would work.
interface State {
currentSongIndex: number;
playlist: Playlist;
}
So now, instead of the currentSongId, we have the currentSongIndex. The current index refers to the index in the playlist list and not the id anymore. With that, we can access the list with the index in O(1) time complexity.
To get the previous song index, we just need to access it by using the currentSongIndex - 1 and the next one by using currentSongIndex + 1. And access the previous and next songs using the new index.
This is how we keep the time complexity of O(1).
So, from one side, we have more normalized data and on the other, we have a more performant approach. We just need to keep in mind that the main feature is playing the current song, and the user will sporadically click “next” or “previous”. Another important piece of information is the average number of songs in the playlist. Let's suppose it's 20 per playlist. So it would not be a big deal.
Performance Optimizations
When thinking about performance optimizations, there is a whole new world of possibilities (with research). We can discuss loading time, rendering time, images, audio optimizations, and so on.
So let's discuss them by topics.
When thinking about loading time, part of the “performance optimization” we deal with while working on the loading experience with skeletons. It's called perceived performance, or the users' notion they are having a faster application even though it's just an intermediate state.
But we can also think about code splitting the application to deliver the bundle the user really needs.
And maybe one of the most impactful decisions is the rendering architecture. Should it be an SPA, SSR, ISP, etc?
A Single Page Application gives a lot of flexibility and improves interactivity for the user, but with that comes a lot of issues. We can talk about render-blocking scripts, all the JavaScript has to be downloaded before it can be run, and because of that, it increases, in ms/seconds, the FCP and LCP metrics. Also, it could also have CLS issues as SPAs are kinda unfairly penalized
For Server Side Rendering apps, if the LCP element (text or image) is attached to the HTML, it will have a big impact on the FCP and LCP scores as it doesn't need to download and execute the whole JavaScript (that can be a huge bundle), the HTML is generated in the server and returned to the browser, so it gets rendered very fast.
One of the SSR's bottlenecks is the cost of hydration. Some would state that hydration is pure overhead and we should think about different ways of using browsers to render pages in an optimal way: Progressive Hydration, Islands Architecture, and React Server Components come to mind.
There are a lot of discussions around this, new frameworks were created, and a lot of buzz on different types of rendering architectures.
Talking about rendering, what we definitely can think about is virtualizing the list of songs. With List virtualization, only a small subset of the list will be rendered in the DOM. When the user scrolls down, the list virtualization will remove and recycle the first items and replace them with newer and subsequent items in the list.
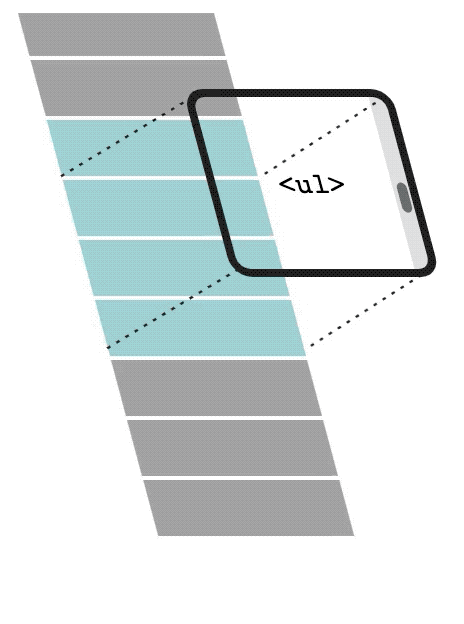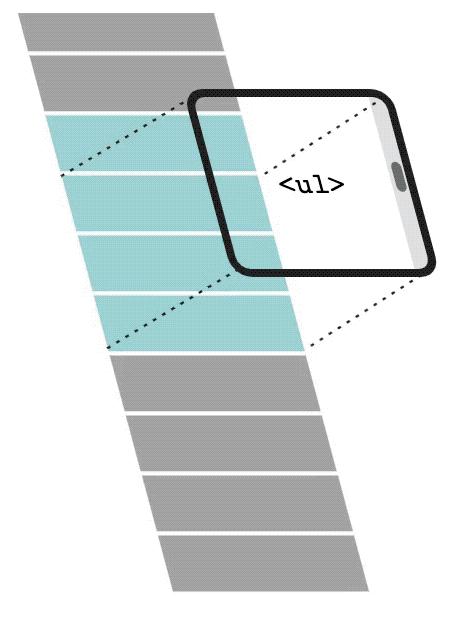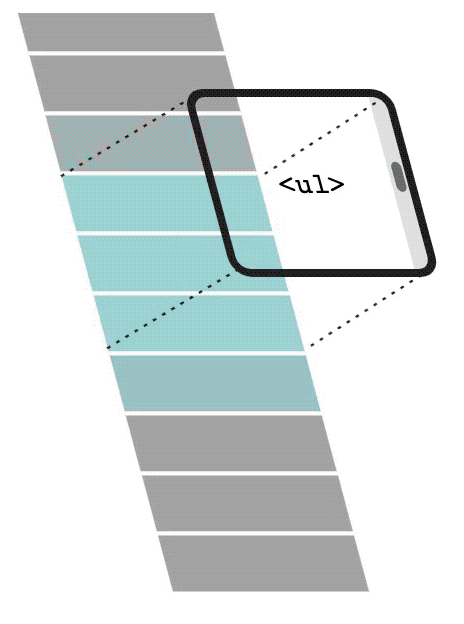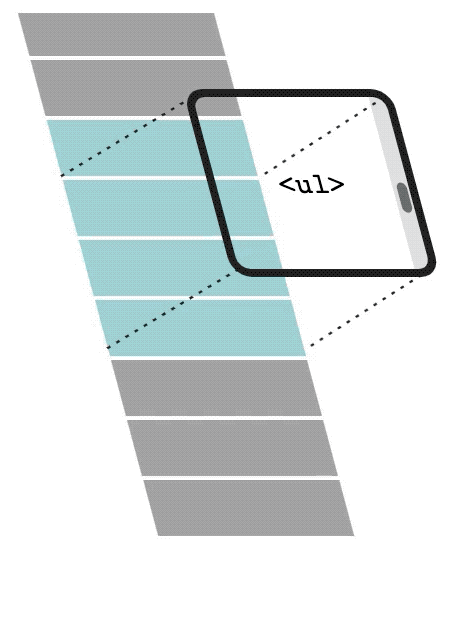
Using this technique can hugely impact user experience, not only the loading time but mostly user interaction metrics like First Input Delay (FID) and Interaction to Next Paint (INP). Having a faster rendering mechanism helps reduce the work of the browser's main thread and the browser being less busy, responds to the user more quickly.
Another technique that could help render data in the UI faster is the usage of the stale-while-revalidate cache. The simpler definition of this mechanism is: we load the cached content right away while updating the cached content to make it fresh for the future. It only updates the cache if it's stale, this is why “stale” (get the cached content that's “stale”) while “revalidate” (update the stale cache to make it fresh).
We can use it in our API request when getting the playlist data. So if the user goes to another page and comes back to the playlist, it will get the content from the cache (and maybe revalidate it if it's stale), making the experience so much faster and smoother.
Another topic we can think about when it comes to performance and making a better user experience is “Image Optimization”.
The first tiny idea is to opt for SVGs over an image (using the image tag) on the “play”, “stop”, “next”, and “previous” buttons. Image requests don't block the main thread but it's one more network request the application needs to handle. In this case, it would be 4 “unnecessary” network requests if you can replace them with SVGs.
Another tiny image performance pattern is to make sure your images are hosted in a CDN so we can get them faster and also from the cache. Also, prefer self-hosting your images:
A less-optimised image served from the same origin is always faster than a more-optimised image from a third party. Self-host your static assets! — Self-Host Your Static Assets
We can also generate different image formats like WebP and AviF for better performance.
The size of images is also important. We need to make sure we won't load a 1mb image for a mobile phone (or even for desktop), or in the words, make our images responsive. To do that, we can use the help of srcset. We provide a bunch of different sizes so the browser can pick the right one. If we don't use an image tool like Cloudinary, we probably need to host the images and generate all possible sizes we expect that can be rendered on the page.
Another image perf technique to improve perceived performance is to request a low-quality image with blur, download a high-quality image in the background and smoothly transition from the low-quality to the high-quality image with the ease-in/ease-out transition.
To do image caching, we can rely on browser caching or setup a service worker to handle the image cache if we need more fine-grained control over the network request. Service workers are interesting because they also provide other benefits like offline experience and more memory and storage space for our origin
Another type of file we can optimize in this particular case is audio files. One way of doing this is to store them in the “file system” if it has access, or in a “client database” like IndexedDB. The audio files would be stored in the browser and if the user has the possibility to download them, we need to think about security and probably implement file encryption which I think starts to get more and more complex for a simple file cache.
Another approach is to use service workers the same way we did for images so we don't need to handle what is stored in the browser.
Final words
Designing new frontend architectures is always a challenge and we should take everything into consideration to choose the best trade-offs.
Clarifying questions is super important because you need to understand the user/system requirements, what you should focus on first, and what you can postpone to a "next version".
Then some patterns start to emerge like building the component tree from the UI mockup, designing the data structures to handle the client state, thinking about the API request and the required payload, and performance optimizations we can do to improve the application.
I hope you could learn about some ideas from this post and maybe use them in your next architectural design or even in future interviews.
Crafting Frontend is a series of posts and experiments I'm doing to craft the art of frontend engineering. To see all the experiments I've been doing, follow the Crafting Frontend github repo.