Essentials of Interpretation: A Compiler Crash Course
 Photo by Mulyadi
Photo by MulyadiThese notes were taken from the Essentials of Interpretation course by Dmitry Soshnikov and it's part of the Essentials of Interpretation series.
Intro
The Essentials of Interpretation course teaches the study of the runtime semantics of programming languages and it is divided into two main parts:
- A crash course on compilers
- The interpreter implementation
Tokenizers, Parsers, ASTs, Interpreters, and Compilers
The tokenizer handles the compiler phase called lexical analysis where it reads the source code and builds tokens from it. It's also called a lexer or scanner.
Generally, the token is represented by an object with two properties: a type and a value. An example:
(print "hello")
The tokens produced from this code are
- An identifier
ID: "print"(typeID, value"print") - A string
String: "hello"(typeString, value"hello")
In this phase, the tokenizer doesn't care about the syntax so it doesn't matter if the syntax is valid or not in this phase. The tokenizer is only responsible to generate tokens based on the source code.
Let's take this code as an example:
if (
This is a broken syntax because the compiler expects a condition right after the open parentheses.
But for the tokenizer, it will run without any error. This is the generated tokens:
keyword: "if"(typekeyword, value"if")op: "("(typeop— open parentheses, value"(")
Now, the parser handles the analysis of the syntax (this phase is also called the syntactic analysis). It produces an intermediate representation (IR) called AST or Abstract Syntax Tree so we can make sense of the code and the syntax.
It's important to notice that in this phase it's still done in static time not in runtime. It's just reading the tokens and producing the so-called AST.
Take a look at this code
x = 10 * 5 + y;
An AST representation for this code would be something similar to this:
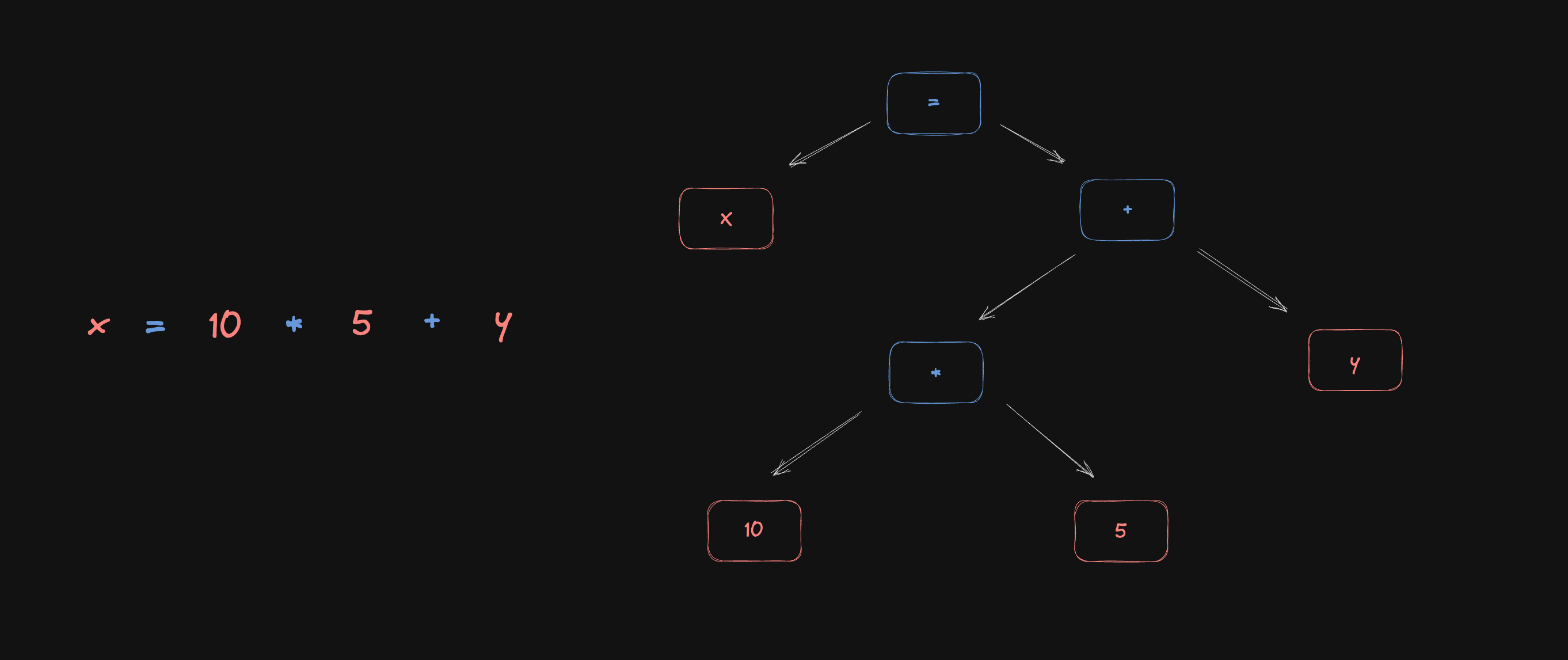
Parsers can be hand-written parsers, generally recursive-descent parsers or automatically generated by parser generators like LL(1)..L(k), PEG, GLR, LR(k). As this course is all about interpretation and semantics, we’re not going too deep into parsers.
Runtime Semantics
What do we study in runtime semantics? It's the study of the meaning of the program or in other words:
- What does it mean to define a variable?
- What does it mean to define a function?
- How does scope work?
- How do functions are called? What's call stack?
- How do you pass parameters?
A clear example of how semantics can be different between languages is the comparison between PHP and JavaScript, where in the comparison below, you can see that in PHP, functions don't “know” about variables defined outside their scope. Now, in JavaScript, all functions are known to be closures so they keep the parent environment so, they can reuse all values defined outside them like variables and functions.
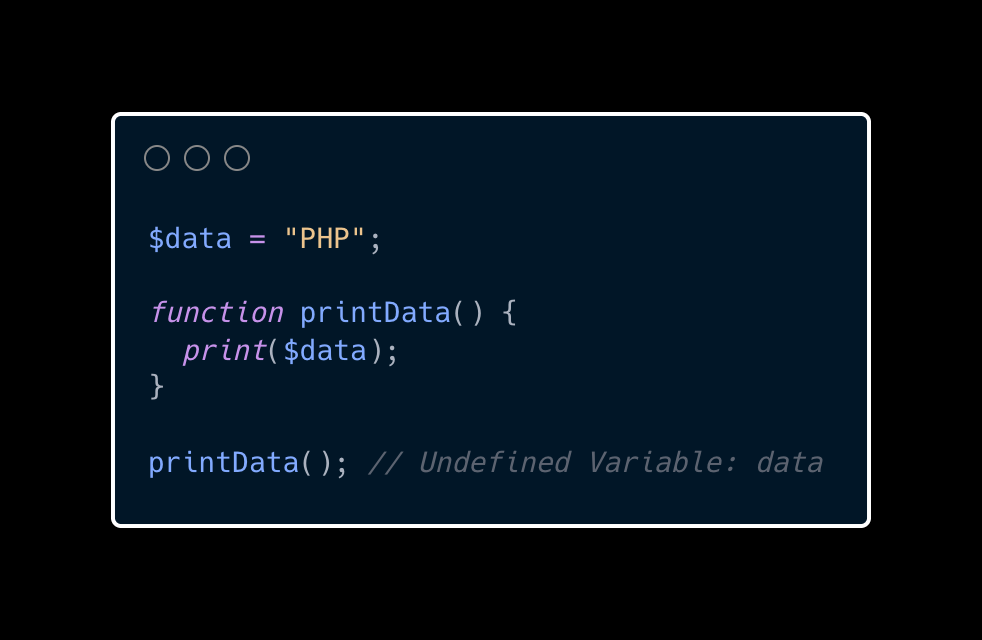

In PHP, we'll get an Undefined variable and in JavaScript, the function “knows” about the outside variable data so it will print its value.
Interpreters vs Compilers
Interpreted languages implement the semantics themselves. They can be AST-based (recursive) interpreters (tree-based data structure) or Bytecode interpreters, also called VMs, or Virtual Machines, where it receives a plain array of code instructions.
Compiled languages don't execute the code, it delegates the semantics to a target language. They can be different kinds of compilers:
- Ahead-of-time (AOT) compilers. e.g. C++
- Just-in-time (JIT) compilers. e.g. JS
- AST-transformers (transpilers) — high-level compilers. e.g. Babel, TypeScript
If you have a program and you need to have the output of this program, you need an interpreter. The compiler translates a program into another one and hopes that it has an interpreter for that. At the low level, the interpreter exists, the CPU.
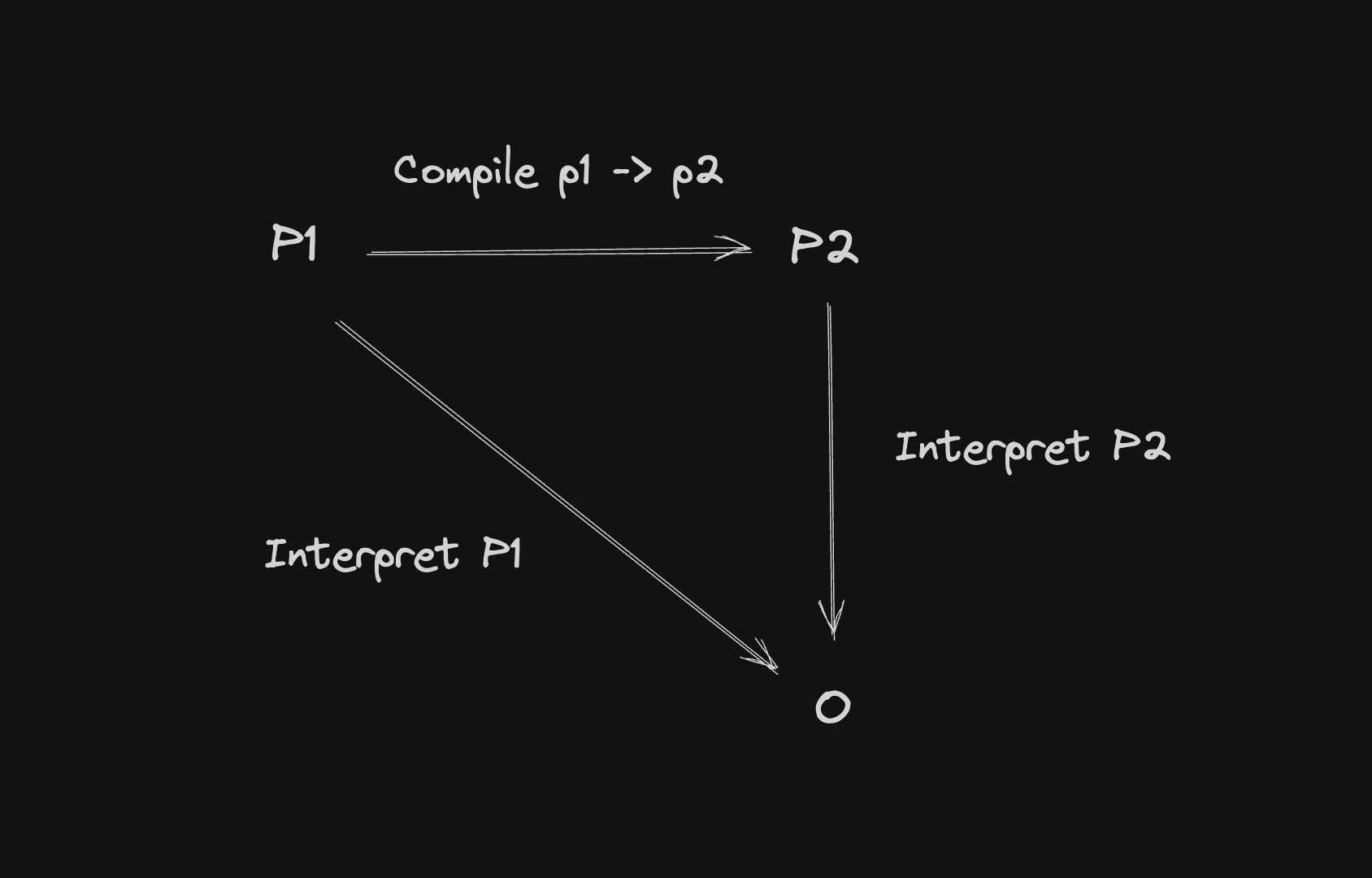
If you compile the code into machine code (x86/x64), the CPU will be able to execute it, so the CPU works as an interpreter running the code and getting the output of the program.
In the illustration above, as an example, you can think of
- P1 as JavaScript and being interpreted to generate an output
- P1 as C++ and being compiled to native code (P2) and the CPU interprets it and generate the output
AST Interpreters and VMs
We're going more in-depth about ASTs but what you need to know about AST-based interpreters now is that they use a tree data structure to represent the source code.
In bytecode-based interpreters (VMs), the difference is the format. It has an extra step called bytecode emitter where it generates bytecode and then they interpret this new format.
VMs are used as an optimization for storage and traversing as bytecode is a plain array of bytes that takes less space and's closer to real machines and AST can take more space and is slower to be traversed.
The types of VMs are:
- Stack-based machines
- Stack for operands and operators
- The result is on top of the stack
- Register-based machines
- Set of virtual registers
- A register is a data storage
- The result is in an accumulator register
- Mapped to real (physical) registers on the machine
Now, there are different ways to represent ASTs. Let's take a look at this code
x = 15;
x + 10 - 5;
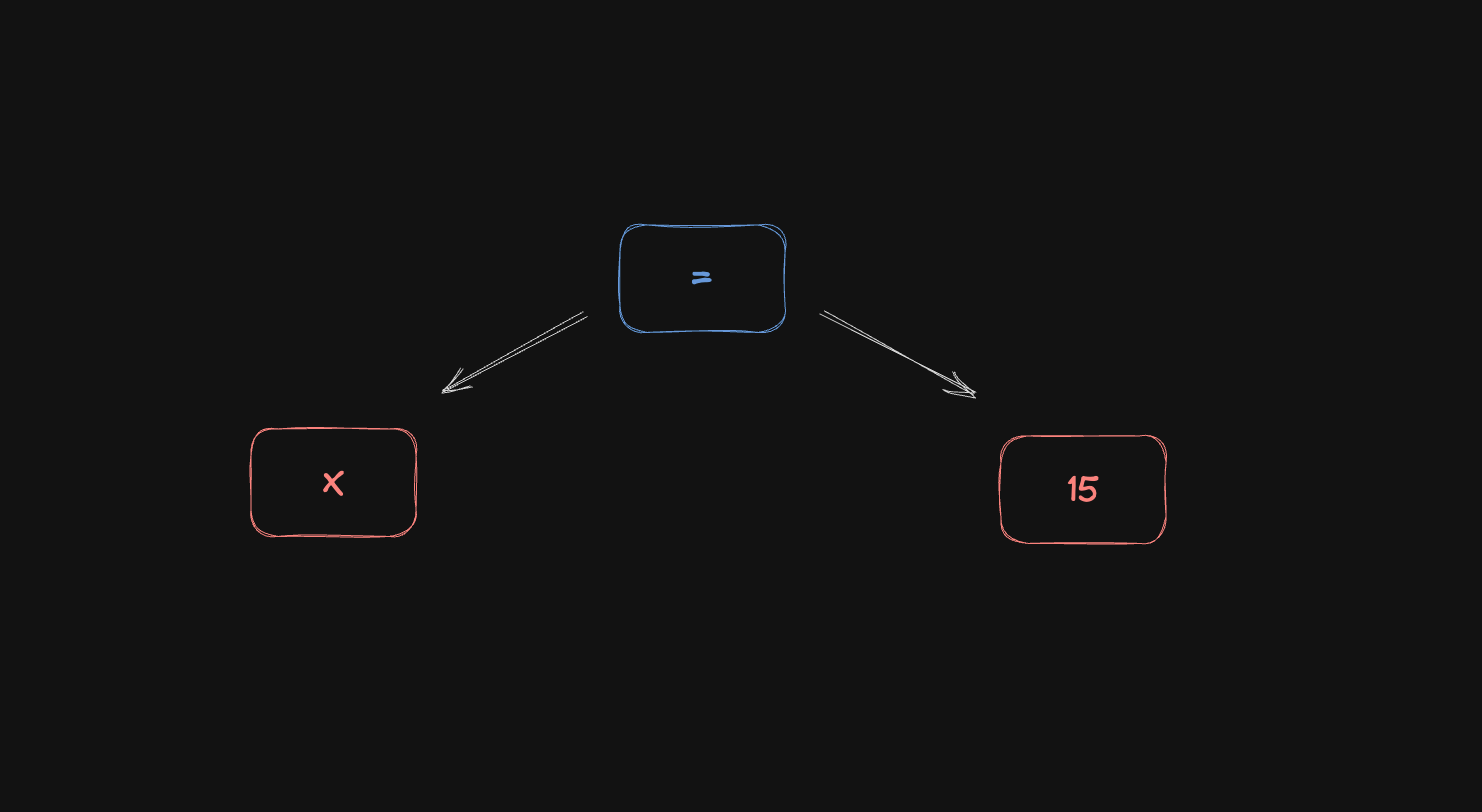
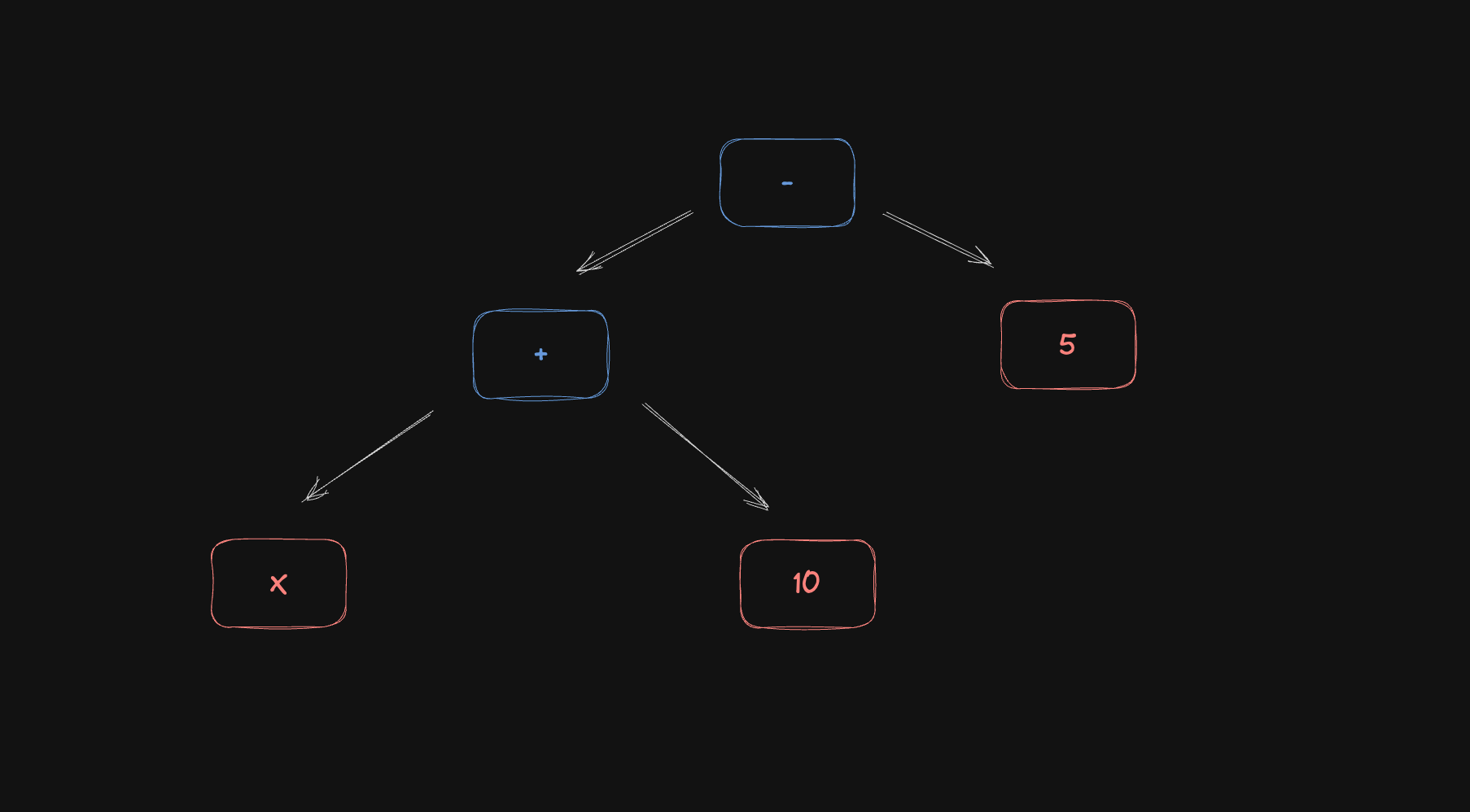
A possible representation is to use "objects" like this:
{
type: "Program",
statements: [
{
type: "Assignment",
left: {
type: "Identifier",
value: "x"
},
right: {
type: "Literal",
value: 15
}
},
{
type: "Binary",
operator: "-",
left: {
type: "Binary",
operator: "+",
left: {
type: "Identifier",
value: "x"
},
right: {
type: "Literal",
value: 10
}
},
right: {
type: "Literal",
value: 5
}
}
]
}
Let's unpack this AST:
- The whole structure is a program with a list of statements
- The first statement is an assignment expression
- The left side of the assignment is the identifier
x - The right side of the assignment is the literal
15
- The left side of the assignment is the identifier
- The second statement is a binary expression
- The binary expression is a subtraction operation (the operator is
-) - The left side is another binary expression
- It's an addition operation, it sums the identifier
xwith the literal10
- It's an addition operation, it sums the identifier
- The right side is a literal
5
- The binary expression is a subtraction operation (the operator is
And there's another way to represent it too: using arrays
We can use arrays to follow this rule:
- The first position will be the statement/expression type. e.g.
assign,sub,add, etc - The second position is the left side of the tree: the left child
- The third position is the right side of the tree: the right child
[
program,
[
[assign, x, 15],
[sub, [add, x, 10], 5],
],
];
In this case,
- We have the program
- The first statement/expression
- 1st position:
assigntype - 2nd position:
xidentifier (left child) - 3rd position:
15literal (right child)
- 1st position:
- The second statement/expression
- 1st position:
subtype - 2nd position: a new node (left child)
- 1st position:
addtype - 2nd position:
xidentifier (left child) - 3rd position:
10literal (right child)
- 1st position:
- 3rd position:
5literal (right child)
- 1st position:
Using arrays makes it visually simpler and more compact. This is the structure we’re going to see in this series.
Compilers — AOT, JIT, Transpiler
In general, compilers can have three types: AOT, JIT, and Transpiler.
The AOT or Ahead Of Time Compiler does ahead-of-time translation. It means that the compilation is done before the execution time (runtime). In the compiler steps, there's a new phase called Code Generator, where the compiler generates a series of IR (Intermediate Representation) and then produces the native code (x86 / x64).
That way the compiler is responsible for generating the native code but the CPU will work as an "Interpreter" and be responsible for executing the native code.
This phase always happens in static time, before execution time, this is why it's called ahead-of-time compilation.
The second type of compiler is the JIT Compiler, or Just In Time Compiler. It handles the translation at runtime which means that the program is being translated when it's being executed.
This type of compilation is a combination of the ahead-of-time compilation and interpretation.
The purpose of JIT compilation is to improve the performance of the heavyweight operations, so if we have a heavyweight function being called multiple times, the compiler generates native code in runtime and when it's called again, the compiler can use the cached version of that compiled program so it doesn't need to through all the steps again.
The last one is the Transpiler or also called AST Transformer. It's a high-level translation, it's the mix of a transformer + a compiler.
The compiler transforms an AST into another AST. It can be the transformation of the same language, e.g. JS to older versions of JS (like Babel and TypeScript do), or a completely different language transformation, e.g. Python to JavaScript, C++ to Java, etc.
Asking if JavaScript, Python, C++, etc are interpreted or compiled languages is the wrong question. What's interpreted or compiled are the implementations, not the language itself.
A language can have multiple ways to be handled. It can be compiled or interpreted using an AST interpreter, Bytecode interpreter, AOT compiler, JIT compiler, or AST transformer. What really matters is if the runtime semantics are preserved. And this is what we're going to study in this series.
Final words
In this first post of the series, we talked about interpreters, compilers, their differences, and different types of compilers and interpreters.
The one important part is that independently of which one we choose, we must preserve the runtime semantics, that's going to be the main topic of this series.
Here are some resources you can use:
- Programming Language Research: a bunch of resources about my studies on Programming Language Theory & Applied PLT
- Essentials of Interpretation repo
- Essentials of Interpretation course
- Compiler Engineering courses